こんにちは。SENSYプロダクト開発チームPdMの岩間です。
SENSYではDWHにBigQueryを使用しており分析やモデル構築において日々大量のクエリが実行されています。 案件ごとにGCP PJTを立ててコストアラートを設定していますが、ユーザー単位でBigQueryの利用状況を確認したい時があります。 そういった際にダッシュボードで簡易的にコストを確認する方法について紹介していきます。
クエリコスト取得
クエリコストの計算にはINFORMATION_SCHEMAのJOBSビューを使用します。
以下のクエリで実行PJTに対してユーザーごとに日別の合計コストを計算することができます。
変数となる部分はコスト計算部分の為替や集計期間です。こちらについてはダッシュボード構築時にパラメータとして設定します。
select date(creation_time, "Asia/Tokyo") as execution_date -- クエリ実行日 ,split(user_email, "@")[OFFSET(0)] as user -- 実行ユーザー ,count(1) as cnt_query -- クエリ回数 ,count(Distinct query) as uniq_query -- 重複なしクエリ回数 ,sum(total_bytes_processed*1e-9) as total_gigabytes_processed --処理データ量GB ,sum(total_bytes_processed*1e-12*6.25*150) as cost -- コスト ,min(timestamp_add(creation_time, interval 9 hour)) as min_execution_datetime ,max(timestamp_add(creation_time, interval 9 hour)) as max_execution_datetime from `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT where date(creation_time, "Asia/Tokyo") >= date_sub(current_date(), interval 1 month) and state = "DONE" and not (query like '%total_bytes_processed%') group by execution_date ,user order by execution_date desc ,user
今回はJOBSビューを使ってユーザーごとに日別の合計コストを計算しましたが、他にも長時間実行中のクエリやコストの高いクエリなどを抽出できるので、ぜひ公式ドキュメントをご覧ください。 cloud.google.com
ダッシュボード構築
コスト計算クエリをデータソースに設定しダッシュボードを構築していきます。 大きく以下3つの作業になります。
- コスト計算クエリをカスタムクエリとしてデータソースに設定
- 為替と集計期間をパラメータとして設定
- グラフを作成
最初にコスト計算クエリをカスタムクエリとして設定します。
この際に為替と集計期間をパラメータにしておくことでダッシュボード側で操作した際に再度集計が走るようにすることが可能です。
クエリでは以下のように@kawase、@interval_monthとして記載します。
select date(creation_time, "Asia/Tokyo") as execution_date -- クエリ実行日 ,split(user_email, "@")[OFFSET(0)] as user -- 実行ユーザー ,count(1) as cnt_query -- クエリ回数 ,count(Distinct query) as uniq_query -- 重複なしクエリ回数 ,sum(total_bytes_processed*1e-9) as total_gigabytes_processed --処理データ量GB ,sum(total_bytes_processed*1e-12*5*@kawase) as cost -- 金額 ,min(timestamp_add(creation_time, interval 9 hour)) as min_execution_datetime ,max(timestamp_add(creation_time, interval 9 hour)) as max_execution_datetime from `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT where date(creation_time, "Asia/Tokyo") >= date_sub(current_date(), interval @interval_month month) and state = "DONE" and not (query like '%total_bytes_processed%') group by execution_date ,user order by execution_date desc ,user
カスタムクエリ設定時にパラメータも以下のように設定します。

あとは折れ線グラフや表を好みで設定してダッシュボード構築完了です。 以下の例では直感的にわかるように時系列でユーザーごとのコストを表示させたり詳細確認用にテーブルを並べたりしています。
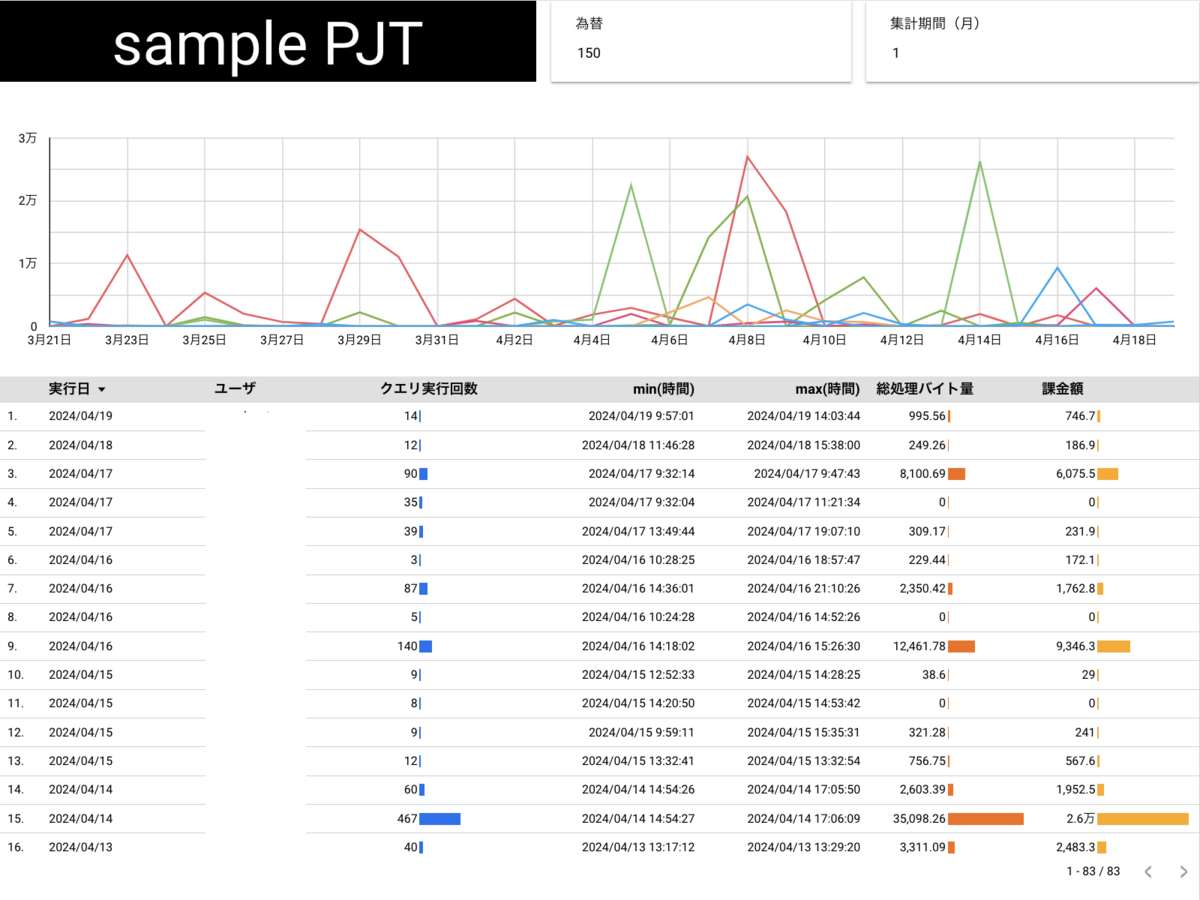
最後に
カスタムクエリはPJTごとに設定できたりパラメータを埋め込むことができるので手間をかけずにインタラクティブなダッシュボードが構築できてとても便利です。(一方で管理しにくくカオスになりがちですが...)
クエリコスト確認の際にはぜひ本記事を参考にしてみてください。